导语
北京航空航天大学吴文峻老师、罗杰老师研究团队在 ECAI 2024 发表研究成果,提出一种基于层次对称性的多智能体强化学习方法,用于提升无人车集群协同控制任务中的样本效率,并在真实物理环境中完成实验验证。该研究通过引NOKOV度量动作捕捉系统进行无人车高精度位姿真值获取,构建了多智能体强化学习算法从仿真走向现实应用的完整实验闭环。
一、研究背景:无人车集群中的多智能体强化学习挑战
实现高样本效率是强化学习研究中的关键问题之一。在多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)中,随着智能体数量的增加,联合状态空间和动作空间呈指数级增长,导致训练过程收敛缓慢、稳定性下降。
将对称性引入多智能体强化学习被认为是缓解该问题的一种有效途径。然而,现有方法大多关注单一层级的对称结构,对于多智能体系统(MAS)在不同层级上同时存在的层次对称性尚缺乏系统研究。在无人车集群协同控制等复杂任务中,这一问题尤为突出。
二、方法概述:层次对称性驱动的多智能体强化学习(HEPN)
针对上述问题,北京航空航天大学吴文峻老师、罗杰老师团队提出了层次等变策略网络(Hierarchical Equivariant Policy Network, HEPN)。该方法通过显式建模多智能体系统中的层次结构,在策略学习过程中保持严格的等变性约束,从而提升多智能体强化学习的样本效率与泛化能力。
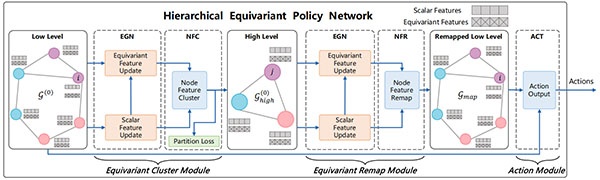
图1 本文提出的 HEPN 的整体框架,包含三个主要模块:1)等变聚类模块,用于提取多智能体系统中的层次结构,将具有相似性的智能体聚类成组,作为高层系统中的智能体;2)等变重映射模块,用于将高层系统中的信息重映射回低层系统;3)动作模块,用于生成最终的动作输出。
HEPN 能够在多智能体协作任务中自动挖掘系统的层次组织形式,并在不同层级之间进行信息交互,为复杂集群系统的协同控制提供了一种新的建模思路。
聚焦多智能体协作任务,本文提出了
1、利用 MAS 中层次对称性来提高 MARL 算法样本效率的 HEPN方法。HEPN 被设计用来探索和学习 MAS 的层次结构,同时确保严格的对称性属性。
2、旨在更好地挖掘 MAS 中层次结构的分区损失;
3、在多个多智能体协作任务中评估了 HEPN 的性能。实验结果表明,HEPN 的收敛速度更快,收敛奖励更高,从而证明了其有效性;
4、在物理多机器人环境中部署了 HEPN,证实了其在现实世界中的有效性。
三、仿真实验验证:多任务、多规模无人车集群协作对比分析
1、不同算法在多智能体协作任务中的表现
在仿真实验中,研究团队选取了多种典型多智能体协作任务,对 HEPN 与多种基线方法进行对比,包括对称性先验方法(ESP)、基于多层感知机的 MAPPO、图神经网络方法 GraphSAGE 以及基于图的协调策略(GCS)。
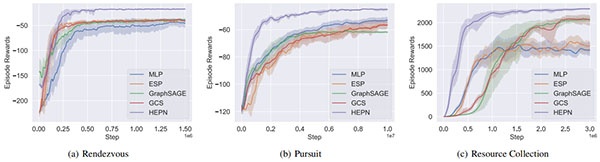
图2 展示了 HEPN、MLP、GraphSAGE、ESP 和 GCS 在三个任务上的学习曲线。每个实验均采用不同的随机种子重复五次,以确保结果的可靠性。
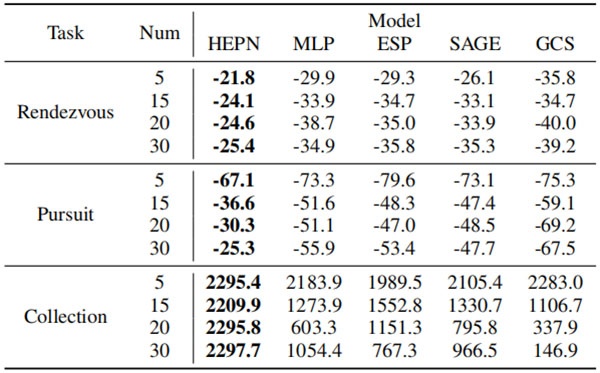
表1 显示了不同数量智能体对不同任务的影响,通过模型的平均收敛奖励来表达
实验结果表明,在不同任务类型和不同智能体规模下,HEPN 方法在收敛速度、收敛奖励以及训练稳定性方面均优于对比方法。
进一步的消融实验显示,引入层次结构对提升多智能体系统在复杂协作任务中的学习效率具有显著作用,而等变性约束在提升算法性能方面发挥了关键影响。
四、现实环境验证:无人车集群的物理实验部署
为验证算法在真实物理环境中的有效性,研究采用 Sim2Real 方法,将在仿真环境中训练完成的 HEPN 模型部署至现实无人车集群系统中,并开展多任务实验验证。
1.无人车集群位姿获取与状态感知
在现实实验中,通过 ROS 对无人车进行控制,并使用 NOKOV 度量动作捕捉系统 获取无人车集群的高精度位姿数据,作为多智能体强化学习算法的实时环境状态输入。该位姿真值数据用于评估算法在真实环境中的执行效果,并确保实验结果的可重复性与可靠性。
2.会合、追捕与资源收集任务实验结果
HEPN 在会和、追捕和资源收集三个任务中的现实实验展示

部署了HEPN训练模型的多智能体无人车集群完成会合任务

部署了HEPN训练模型的多智能体无人车集群完成追捕任务

部署了HEPN训练模型的多智能体无人车集群完成资源收集任务
研究分别在会合任务、追捕任务和资源收集任务中,将 HEPN 与各任务中表现最佳的基线算法进行对比。实验结果显示,HEPN 在真实无人车集群环境中能够更快完成协作任务,验证了其在物理系统中的有效性与实用性。
五、研究结论与应用意义
该研究通过引入层次对称性建模方法,有效提升了多智能体强化学习在无人车集群协同任务中的样本效率,并在真实物理环境中完成了系统验证。结合高精度位姿真值获取手段,该工作为多智能体强化学习算法从仿真研究走向现实应用提供了一种可复现的实验范式。
相关成果可为群体机器人协同控制、无人系统集群调度以及复杂多智能体系统的工程验证提供参考。
六、北航发表多智能体强化学习样本效率提升方法FAQ
Q1:多智能体强化学习在无人车集群中面临的主要挑战是什么?
A:在无人车集群等多智能体系统中,多智能体强化学习面临的核心挑战是样本效率低。随着智能体数量增加,联合状态空间和动作空间呈指数级增长,导致训练过程收敛缓慢、稳定性不足,难以直接应用于真实物理环境
Q2:什么是层次对称性,它如何提升多智能体强化学习的样本效率?
A:层次对称性是指多智能体系统在不同层级结构上同时保持对称性。通过在策略网络中显式建模这种层次结构,可以减少冗余状态表示,提高策略泛化能力。本文提出的层次等变策略网络(HEPN)正是利用层次对称性,有效提升了多智能体强化学习在协作任务中的样本效率。
Q3:HEPN 方法在无人车集群任务中相比传统方法有哪些优势?
A:在多无人车协同任务中,HEPN 相比 MAPPO、GraphSAGE、ESP 和 GCS 等方法,表现出更快的收敛速度、更高的收敛奖励以及更强的训练稳定性。实验结果表明,HEPN 在处理大规模、多任务的无人车集群协作问题时具有明显优势。
Q4:多智能体强化学习算法如何在真实无人车集群中进行验证?
A:本文采用 Sim2Real 方法,将在仿真环境中训练好的多智能体强化学习模型部署至真实无人车集群。通过 ROS 对无人车进行控制,并在真实环境中执行会合、追捕和资源收集等协作任务,从而验证算法在现实场景中的有效性
Q5:为什么真实环境实验需要高精度位姿真值数据?
A:在多智能体强化学习的真实实验中,算法性能高度依赖于环境状态的准确性。无人车集群的位姿误差会直接影响策略评估结果,因此需要高精度、低延迟的位姿真值数据来确保实验结论的可靠性。
Q6:无人车集群实验中的位姿数据是如何获取的?
A:在该研究中,无人车集群的实时位姿数据由 NOKOV度量动作捕捉系统 提供。该系统用于获取高精度的无人车集群位姿真值数据,为多智能体强化学习算法在真实环境中的验证提供可靠的环境状态输入。
Q7:NOKOV 度量动作捕捉在多智能体强化学习实验中起到什么作用?
A:NOKOV度量动作捕捉系统在实验中作为环境状态感知与位姿真值获取系统,为无人车集群提供实时、精准的位姿数据。这使得多智能体强化学习算法能够在真实物理环境中稳定运行,并确保实验结果具有可重复性和可信度。
Q8:该研究对群体机器人和无人系统领域有哪些应用价值?
A:该研究为多智能体强化学习算法在真实无人系统中的部署提供了可行路径。通过结合层次对称性建模与高精度动作捕捉系统,可为群体机器人、无人车集群协同控制以及复杂多智能体系统的现实应用提供可靠的实验和评估方法。
七、参考文献
Tian, Yongkai, et al. Exploiting Hierarchical Symmetry in Multi-Agent Reinforcement Learning.
Proceedings of ECAI 2024, IOS Press, 2024, pp. 2202–2209.



