随着具身智能发展迈入深水区,中国创新力量正加速走向世界舞台中央。
近日,由清华大学智能产业研究院(AIR)DISCOVER Lab联合谋先飞技术、原力灵机、求之科技及地瓜机器人共同研发的新一代国产仿真器GS-Playground正式被机器人领域国际顶级学术会议RSS 2026(Robotics:Science and Systems)录用,标志着国内具身智能仿真基础设施在视觉保真度与训练吞吐量两个维度上同时取得了国际领先水平的突破。
痛点突围:为何机器人总是“眼高手低”
当前,具身AI研究正在经历从”本体感知”到”视觉感知”的范式转移。让机器人像人一样”用眼睛看世界”来学习决策成为学界公认的下一代技术路线。然而,现有仿真器在试图提供高保真视觉反馈时,往往面临渲染开销过于高昂、仿真资产制作极度依赖人工、Sim2Real 迁移鸿沟显著三大瓶颈,计算成本和工程复杂度仍处于较高水平。
针对这一行业瓶颈,GS-Playground通过全栈架构创新,将照片级视觉反馈的计算成本大幅降低至可规模化水平,为视觉机器人学习让视觉强化学习首次达到了此前只有本体感知强化学习才能实现的训练规模。
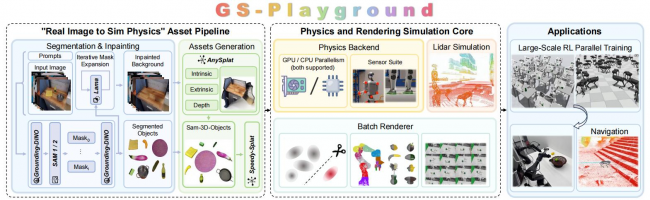
GS-Playground 架构图
技术硬核:三大核心技术破解行业痛点
GS-Playground并非对现有功能的简单叠加,而是从物理求解器、渲染后端到资产管线的全栈系统性重构。
GS-Playground搭载了由谋先飞国产自研的高性能并行物理引擎,它不再单纯追求数学上的平滑,而是更忠实于物理世界的几何真相。无论是波士顿动力Spot机器人的大步跨越,还是精密的抓握手势,它都能带来极高的稳定性。更令人惊叹的是其渲染技术的革新——利用3D高斯泼溅技术,它像一位高效的画家,只保留对视觉理解最关键的信息,在单张消费级显卡上就能驱动2048 个并行场景同时运转,并实现了万帧级的实时渲染。这意味着,机器人可以在几乎不占用过多算力的情况下,看到接近照片般真实的纹理与光影。
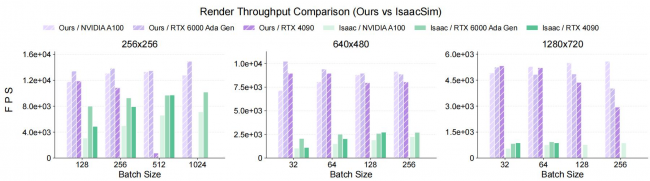
GS-Playground 与 Isaac Sim 光线追踪渲染器在不同分辨率下的渲染吞吐量对比
除了“看”得清,还要“造”得快。以往构建一个仿真场景,需要人工耗费大量时间建模、贴图、调整物理属性,这被称为“数字孪生”的最后一公里难题。GS-Playground引入了一条全自动化的“Image-to-Physics”流水线,只需输入一张普通的RGB图片,AI就能在几分钟内自动识别出物体、补全背景、生成三维结构并赋予其物理属性。这种“所见于所得”的能力,极大地降低了具身智能的研发门槛。
全任务验证:从仿真到现实的零微调跨越
作为当前唯一基于3DGS表示的并行LiDAR仿真器。在实操验证中,GS-Playground展示了令人瞩目的迁移效果。
对于Unitree Go2四足机器人,策略在10分钟内即可收敛,并成功部署至真机实现精准的速度跟踪。对于更复杂的23自由度Unitree G1人形机器人,行走策略在约6小时内完成训练并顺利迁移。最具有说服力的是视觉抓取任务,直接从RGB图像学习端到端6自由度关节控制策略,在未经任何简化的真实场景中实现了 90%的零微调成功率——作为对照,使用同类仿真器训练的策略在真实世界中的成功率均为0%。此外,在视觉导航任务中,Unitree Go2仅依靠机载摄像头即可完成目标导向导航。GS-Playground真正做到了让机器人在虚拟中学到的“手艺”,到了现实中依然好用。

目前,GS-Playground已经成为开源方向上技术栈最完整、Sim2Real验证最充分的平台之一。未来,GS-Playground将通过完整开源全栈框架及 Bridge-GS 数据集,构建起一个开放的创新生态,成为孕育下一代通用机器人的“摇篮”,与更多开发者一起教会机器人认识世界,为具身智能产业提供坚实的发展底座。



